常用的发表偏倚衡量方法(简述病因研究中的偏倚的种类及控制措施)
1.简述病因研究中的偏倚的种类及控制措施有哪些
定义及种类:偏倚是在研究中(从设计到执行的各环节)的系统误差及解释结果的片面性而造成的,使研究结果与其真值出现了某些差值。
因为它是由系统误差所造成,加大样本并不能使之减少。一旦造成事实,则无法消除其影响。
因此,必须认识偏倚,从设计起直到整个研究过程均要加以控制。病因研究中的偏倚有10种以上,它们可以归纳为选择性偏倚、信息(测量、观察)性偏倚及混杂(混淆)性偏倚。
(一)选择性偏倚(selection bias) 在选择研究对象时,试验组和对照组的设立(纳入标准)不正确,使得这两组人在开始时即存在处理因素以外的重大差异,从而产生偏倚。常见的主要有:1.就诊机会偏倚(入院率偏倚,admissionrate bias)由于疾病严重程度不同、就医条件不同、人群对某一疾病的了解和认识程度不同等原因而使患不同种类疾病的人(或有某种特性者)的住院率不同。
从医院选取对照时,如果没有注意到此点,则可引起偏倚。此种偏倚首先由Berkson发现并记述,因此,将此种偏倚又称为Berkson偏倚或Berkson谬误(fallacy)。
2.现患病例及新发病例偏倚(prevalence-incidencebias,又叫Neyman bias)此种偏倚易出现在病程较短的严重致死性疾病,如心肌梗死,部分病例在送到医院前已死亡,如果只以存活的现患病例为对象,研究某因素的作用,必然产生偏倚。这些死亡病例通常未计入心肌梗死总发病人数中,以至于所报道的患病数少于实际的发病数。
又如,在病例对照研究中有意或无意排除(或加入)某些病例,也可出现偏倚,如研究吸烟与肺癌的关系时,对照组包括了慢性支气管炎和冠心病,由于此二病均与吸烟有关,所以吸烟与肺癌的OR减低,甚至于看不出吸烟作为肺癌的病因作用。患病后改变生活习惯也可以使用病例对照方法探讨病因出现偏倚,如患肺癌后戒烟,患高血压后将饮食口味调淡、不吃动物脂肪(肥肉)、适当增加体力活动等等,都可在病例对照研究中使这些因素的病因作用被抵消。
又如,乳腺癌与利血平关系的病例对照研究,在对照组中排除了心血管病人(其中有相当多的高血压病人,他们服用利血平),所以得出利血平是乳腺癌的危险因素的结论。另一个研究将全部病例均纳入,则未发现此相关。
3.检出信号偏倚(detectionsignal bias,unmasking bias)某因素如能引起或促进某症候(与所研究疾病的体征或症状类似)的出现,使患者因此而去就医,这就提高了该病的检出机会,使人误以为某因素与该病有因果联系。这种虚假联系造成的偏倚称为检出信号(或检出症候)偏倚。
如,曾有研究发现子宫内膜癌与绝经期服用雌激素有关。这个研究结果是因为绝经期妇女服用雌激素会引起不规则子宫出血,因此而就医,得到检查子宫内膜的机会较多,从而增加了发现子宫内膜癌的机会。
不服用雌激素的子宫内膜癌常无明显症状,发现机会较少。以刮宫或子宫切除作为诊断子宫内膜癌的诊断时,绝经期服用雌激素的OR为1.7,而以子宫出血就诊者的OR为9.8,二者相差悬殊。
显然,以子宫出血就诊增高了OR。此类偏倚即检出信号偏倚。
4.无应答偏倚(non-responsebias)即研究对象对研究内容产生不同的反应而造成的偏倚。如用通信方式调查吸烟情况,不吸烟者与吸烟者的应答率可以相差悬殊。
无应答者的暴露或患病状况与应答者可能不同。如果无应答者比例较高,则使以有应答者为对象的研究结果可能存在严重偏倚。
所以在研究报告中必须如实说明应答率,并评价其对结果可能造成的影响。与一部分人无应答相反的情况是有一部分人特别乐意或自愿接受调查或测试。
这些人往往是比较关心自身健康或自觉有某种疾病,而想得到检查机会的人。他们的特征或经历不能代表目标人群。
由此造成的偏倚称为志愿者偏倚(volunteer bias)。总之,无论什么原因使观察组与对照组成员不是来自同一总体,即可造成除研究因素以外的有关因素在两组分布不均衡,从而造成选择偏倚。
(二)衡量偏倚(measurement bias)或信息偏倚(information bias) 对观察组和对照组进行观察或测量时存在频度和(或)强度的差异,而使最终判断结果时出现偏倚。在非盲法观察时,由于观察者知道谁在观察组,、谁在对照组,更易出现此种偏倚。
1.回忆偏倚(recall bias)特别是在病例对照研究中,需要被观察者回忆过去的情况(甚至久远的情况,如癌的病因学研究),回忆的准确性会受到影响。病例组可能回忆仔细(特别是当怀疑某因素与某病有关时,如吸烟、被动吸烟与某些癌的关系,口服避孕药与下肢血栓性静脉炎、服雌激素与子宫内膜癌等),而对照组回忆则可能不那么仔细,尤其当研究者屡次提醒病例组有否这些因素时(诱导其回答,更容易出现偏倚-寻因性偏倚)。
有时某种症状或状态的存在会诱导产生或加强其与某种因素的联系,如前段所举子宫内膜癌,得出与口服雌激素有联系的结论即属此,称为疑因性偏倚(exposure suspicion bias)。2.疑诊偏倚 当观察者已知被观察者的某些情况时,在研究时会自觉不自觉地侧重询问、检查有关情况(如对服口服避孕药的妇女,仔细检查其有无下肢血栓性静脉炎,而对有下肢血栓性静。
2.如何进行敏感性分析和发表偏倚分析
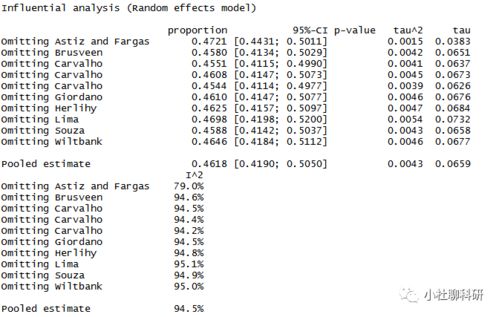
敏感性分析一般以Meta分析结果所绘制的森林图为依据,把肉眼可见的与总体样本95%CI分布差异相对较大的研究(由最明显的开始)予以排除直至可用固定效应模型分析为止(即I方值小于等于50%,同时P大于等于0.1),如敏感性分析后依然无法用固定效应模型分析,则需通过继续逐一排除剩余数据样本以动态观测Meta分析结果变化,如结果变化不大(具体标准暂未在2014版考克兰系统评价员手册中有体现,我个人则是以I方和RR/SMD等统计量变化率作为判断标准),则说明数据合并后稳健性可,可采用随机效应模型作Meta分析,所得结论有效,但不宜过于绝对。
而敏感性分析不宜排除过多数量的数据样本,我个人以50%作临界值,如一个结局指标需要排除至少50%的纳入研究数据样本,方能使数据合并结果稳健,则说明原始纳入研究异质性大,无法明确所有纳入研究在该结局指标的测量标准、方法基本一致。同时敏感性分析后剩余数据样本数我个人认为最好大于等于3,以便能获取较有说服力的Meta分析结果。
当然我也比较同意上一个答案的观点,敏感性分析的纳入研究排除标准可参照Jadad质量评分或RoB风险偏倚评估结果,但我认为应补充一个前提:纳入研究中需有相当部分高质量研究,即Jadad评分大于等于4分(满分7分)或符合Standard RCT标准(兼有随机化、盲法、安慰剂三要素),如纳入研究方法学质量普遍不高,则通过参照方法学质量评价结果进行敏感性分析的做法意义不大。
发表性偏倚目前主要通过倒漏斗图法判断,当然也有Egger&Begger's Test,可将偏倚程度量化(适用于纳入数据数小于10的结局指标,然而RevMan无法做此检验),发表性偏倚一般用于对纳入数据样本数(敏感性分析后)大于等于10结局指标的讨论。
个人的小小体会:系统评价/Meta分析并没有太多固定的模版,每个研究者所关注的点可以不一样,但最好做到有理有据,能自圆其说。
以上谨为个人粗浅看法,如有纰漏之处,欢迎指正!
3.预防医学控制混杂偏倚的方法有哪些
偏倚是在研究中(从设计到执行的各环节)的系统误差及解释结果的片面性而造成的,使研究结果与其真值出现了某些差值。因为它是由系统误差所造成,加大样本并不能使之减少。一旦造成事实,则无法消除其影响。因此,必须认识偏倚,从设计起直到整个研究过程均要加以控制。病因研究中的偏倚有10种以上,它们可以归纳为选择性偏倚、信息(测量、观察)性偏倚及混杂(混淆)性偏倚。
衡量偏倚(measurement
bias)或信息偏倚(information
bias)
对观察组和对照组进行观察或测量时存在频度和(或)强度的差异,而使最终判断结果时出现偏倚。在非盲法观察时,由于观察者知道谁在观察组,、谁在对照组,更易出现此种偏倚。
1.回忆偏倚(recall
bias)特别是在病例对照研究中,需要被观察者回忆过去的情况(甚至久远的情况,如癌的病因学研究),回忆的准确性会受到影响。病例组可能回忆仔细(特别是当怀疑某因素与某病有关时,如吸烟、被动吸烟与某些癌的关系,口服避孕药与下肢血栓性静脉炎、服雌激素与子宫内膜癌等),而对照组回忆则可能不那么仔细,尤其当研究者屡次提醒病例组有否这些因素时(诱导其回答,更容易出现偏倚-寻因性偏倚)。有时某种症状或状态的存在会诱导产生或加强其与某种因素的联系,如前段所举子宫内膜癌,得出与口服雌激素有联系的结论即属此,称为疑因性偏倚(exposure
suspicion
bias)。
2.疑诊偏倚 当观察者已知被观察者的某些情况时,在研究时会自觉不自觉地侧重询问、检查有关情况(如对服口服避孕药的妇女,仔细检查其有无下肢血栓性静脉炎,而对有下肢血栓性静脉炎的妇女仔细询问其口服避孕药的历史)就可能得出二者有联系的结论。但实际上可能是偏倚所致。
3.沾染偏倚(contamination
bias)对照组成员有意或无意应用了试验组的措施。如用低钠盐减少钠摄入与高血压关系的研究时,对照组成员同样可以购得低钠盐(因接受宣传后认为低钠盐可以防止高血压),从而使判断结果时出现偏倚(沾染性偏倚)。试验组成员有意或无意接受了研究因素以外的措施,而使结果有利于试验组,称为干扰。干扰与沾染最容易在非盲法观察的条件下发生。
4.预防医学控制混杂偏倚的方法有哪些
偏倚是在研究中(从设计到执行的各环节)的系统误差及解释结果的片面性而造成的,使研究结果与其真值出现了某些差值。
因为它是由系统误差所造成,加大样本并不能使之减少。一旦造成事实,则无法消除其影响。
因此,必须认识偏倚,从设计起直到整个研究过程均要加以控制。病因研究中的偏倚有10种以上,它们可以归纳为选择性偏倚、信息(测量、观察)性偏倚及混杂(混淆)性偏倚。
衡量偏倚(measurementbias)或信息偏倚(informationbias) 对观察组和对照组进行观察或测量时存在频度和(或)强度的差异,而使最终判断结果时出现偏倚。在非盲法观察时,由于观察者知道谁在观察组,、谁在对照组,更易出现此种偏倚。
1.回忆偏倚(recallbias)特别是在病例对照研究中,需要被观察者回忆过去的情况(甚至久远的情况,如癌的病因学研究),回忆的准确性会受到影响。病例组可能回忆仔细(特别是当怀疑某因素与某病有关时,如吸烟、被动吸烟与某些癌的关系,口服避孕药与下肢血栓性静脉炎、服雌激素与子宫内膜癌等),而对照组回忆则可能不那么仔细,尤其当研究者屡次提醒病例组有否这些因素时(诱导其回答,更容易出现偏倚-寻因性偏倚)。
有时某种症状或状态的存在会诱导产生或加强其与某种因素的联系,如前段所举子宫内膜癌,得出与口服雌激素有联系的结论即属此,称为疑因性偏倚(exposuresuspicionbias)。 2.疑诊偏倚 当观察者已知被观察者的某些情况时,在研究时会自觉不自觉地侧重询问、检查有关情况(如对服口服避孕药的妇女,仔细检查其有无下肢血栓性静脉炎,而对有下肢血栓性静脉炎的妇女仔细询问其口服避孕药的历史)就可能得出二者有联系的结论。
但实际上可能是偏倚所致。 3.沾染偏倚(contaminationbias)对照组成员有意或无意应用了试验组的措施。
如用低钠盐减少钠摄入与高血压关系的研究时,对照组成员同样可以购得低钠盐(因接受宣传后认为低钠盐可以防止高血压),从而使判断结果时出现偏倚(沾染性偏倚)。试验组成员有意或无意接受了研究因素以外的措施,而使结果有利于试验组,称为干扰。
干扰与沾染最容易在非盲法观察的条件下发生。
5.简述常用的抽样方法有哪些
四种基本的抽样方法:
1.单纯随机抽样:单纯随机抽样是在总体中以完全随机的方法抽取一部分观察单位组成样本(即每个观察单位有同等的概率被选入样本)。常用的办法是先对总体中全部观察单位编号,然后用抽签、随机数字表或计算机产生随机数字等方法从中抽取一部分观察单位组成样本。
其优点是简单直观,均数(或率)及其标准误的计算简便;缺点是当总体较大时,难以对总体中的个体一一进行编号,且抽到的样本分散,不易组织调查。
2.系统抽样:系统抽样又称等距抽样或机械抽样,即先将总体中的全部个体按与研究现象无关的特征排序编号;然后根据样本含量大小,规定抽样间隔k;随机选定第i(i
系统抽样的优点是:易于理解,简便易行;容易得到一个在总体中分布均匀的样本,其抽样误差小于单纯随机抽样。缺点是:抽到的样本较分散,不易组织调查;当总体中观察单位按顺序有周期趋势或单调增加(减小)趋势时,容易产生偏倚。
3.整群抽样:整群抽样是先将总体划分为K个“群”,每个群包含若干个观察单医学教|育网搜集整理位,再随机抽取k个群(k
整群抽样的优点是便于组织调查,节省经费,容易控制调查质量;缺点是当样本含量一定时,抽样误差大于单纯随机抽样。
4.分层抽样:分层抽样是先将总体中全部个体按对主要研究指标影响较大的某种特征分成若干“层”,再从每一层内随机抽取一定数量的观察单位组成样本。
分层随机抽样的优点是样本具有较好的代表性,抽样误差较小,分层后可根据具体情况对不同的层采用不同的抽样方法。
四种抽样方法的抽样误差大小一般是:整群抽样≥单纯随机抽样≥系统抽样≥分层抽样。
在实际调查研究中,常常将两种或几种抽样方法结合使用,进行多阶段抽样。
6.请教几个meta分析的问题
进行Meta分析过程中产生的偏倚。
第一大类:原始文献存在的偏倚,也就是试验中偏倚,包括6类:选择偏倚、实施偏倚、损耗偏倚、测量偏倚、报告偏倚和其他偏倚。
1. 选择偏倚(selection bias)
发生在选择和分配研究对象时;
采用随机分配和分配隐藏的方法可降低选择性偏倚;
但如果分配隐藏不当,可能会过度估计研究结果。
2. 实施偏倚(performance bias)
发生在干预措施的实施过程中;
系统误差造成;
对研究者和研究对象采用盲法可以避免实施偏倚;
但如果对研究对象不盲,可能会过度估计研究结果。
3.损耗偏倚(attrition bias)
发生在研究随访过程中,由于失访、退出、无应答原因;
采用合适的统计学方法,如ITT分析,可减少损耗偏倚。
4. 测量偏倚(detection bias)
发生在结果测量和分析时;
对研究结果,可夸大疗效达到17%-35%;
一方面,采用统一、标准化测量的方法,可避免测量偏倚;
另一方面,对研究对象和测量者实施盲法,也可避免测量偏倚。
5.报告偏倚(reporting bias)
发生在报告研究结果时;
进行研究注册可避免报告偏倚。
6. 其他偏倚(other bias)
引起高度偏倚风险的其他因素;
也是依靠研究注册,根据计划书与全文对比来判断。
第二大类:Meta分析的偏倚,也就是进行Meta分析过程中产生的偏倚。
根据Felson分类法有三种:
1. 抽样偏倚(sampling bias)
发生在查找相关文献时;
包括7个方面:
Ø发表偏倚(publication bias):是Meta分析中影响结果有效性的主要原因,较难控制,是指研究结果的性质和方向导致研究成果的发表与未发表引起的偏倚;
Ø索引偏倚(index bias):由于数据库中数据标引不准确而导致文献漏检;
Ø查找偏倚(search bias):由于检索方法原因导致漏检或误检文献;
Ø参考文献偏倚(reference bias):依赖综述或参考文献目录查找文献时导致的;
Ø重复发表偏倚(multiple publication bias)和主题多重复偏倚(multiply used subjects bias):某项研究分2篇或多篇以系列形式发表而导致的;
Ø英语语种偏倚(english language bias):检索文献时,由于限定英语文献而导致的;
Ø数据提供偏倚(bias in provision of data):未搜集会议论文、学位论文等散在文献而导致的。
减少抽样偏倚的方法就是:文献检索时要查全、查新、查准,这也是我们做一篇高质量Meta分析报告的基础吧;
需要考虑的具体因素,在LinkLab 12月6日文章“一文搞定Meta分析”已做详细介绍,各位看官不妨再回顾下。
2. 选择偏倚(selection bias)
发生在根据文献纳入/排除标准选择符合分析的文献时;
包括:纳入标准偏倚和选择者偏倚;
尽量制定明确的、严格统一的文献纳入/排除标准,可减少选择偏倚;
两人以上采用盲法独立选择文献,也可减少选择偏倚;
还可以采用敏感性分析,考察不同的文献纳入/排除标准对Meta分析结果的影响。
3.研究内偏倚(within study bias)
发生在资料提取时;
包括3方面:
Ø提取者偏倚
Ø研究质量评价偏倚
Ø报告偏倚
两人以上独立盲法提取资料,有专门提取数据的表格,一般包括基本信息、研究特征、结果测量等,明确各数据及质量评价统一标准,可降低本偏倚。
此外,Meta分析的偏倚,还有Cochrane分类法,其强调主要通过报告偏倚来衡量纳入研究的完整性,并将报告偏倚分为:发表偏倚、时滞偏倚、多重/重复发表偏倚、发表位置偏倚、引用偏倚、语言偏倚、结果报告偏倚。根据上面的介绍,大家应该也不难理解引起这些偏倚的原因。
在这些偏倚中,研究最多的就是发表偏倚,它也是影响Meta分析质量的很重要因素。对于它的识别和处理,下期我们继续哦……