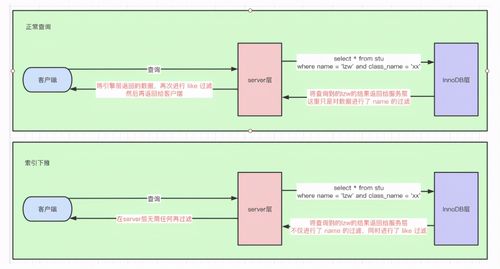
创建索引(关于mysql建立索引需要注意的几点事项)
1.关于mysql建立索引需要注意的几点事项
1.索引不存储null值。
更准确的说,单列索引不存储null值,复合索引不存储全为null的值。索引不能存储Null,所以对这列采用is null条件时,因为索引上根本没Null值,不能利用到索引,只能全表扫描。
为什么索引列不能存Null值?将索引列值进行建树,其中必然涉及到诸多的比较操作。Null值的特殊性就在于参与的运算大多取值为null。
这样的话,null值实际上是不能参与进建索引的过程。也就是说,null值不会像其他取值一样出现在索引树的叶子节点上。
2.不适合键值较少的列(重复数据较多的列)。假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。
再加上访问索引块,一共要访问大于200个的数据块。如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。
3.前导模糊查询不能利用索引(like '%XX'或者like '%XX%')假如有这样一列code的值为'AAA','AAB','BAA','BAB' ,如果where code like '%AB'条件,由于前面是模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫描。
如果是这样的条件where code like 'A % ',就可以查找CODE中A开头的CODE的位置,当碰到B开头的数据时,就可以停止查找了,因为后面的数据一定不满足要求。这样就可以利用索引了。
4.MySQL主要提供2种方式的索引:B-Tree索引,Hash索引。B树索引具有范围查找和前缀查找的能力,对于有N节点的B树,检索一条记录的复杂度为O(LogN)。
相当于二分查找。哈希索引只能做等于查找,但是无论多大的Hash表,查找复杂度都是O(1)。
显然,如果值的差异性大,并且以等值查找(=、、in)为主,Hash索引是更高效的选择,它有O(1)的查找复杂度。如果值的差异性相对较差,并且以范围查找为主,B树是更好的选择,它支持范围查找。
2.数据库索引的注意事项
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改操作远远多于检索操作时,不应该创建索引。

3.关于mysql建立索引需要注意的几点事项
1.索引不存储null值。
更准确的说,单列索引不存储null值,复合索引不存储全为null的值。索引不能存储Null,所以对这列采用is null条件时,因为索引上根本没Null值,不能利用到索引,只能全表扫描。
为什么索引列不能存Null值?
将索引列值进行建树,其中必然涉及到诸多的比较操作。Null值的特殊性就在于参与的运算大多取值为null。这样的话,null值实际上是不能参与进建索引的过程。也就是说,null值不会像其他取值一样出现在索引树的叶子节点上。
2.不适合键值较少的列(重复数据较多的列)。
假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。
再加上访问索引块,一共要访问大于200个的数据块。
如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一些,肯定就不会利用索引了。
3.前导模糊查询不能利用索引(like '%XX'或者like '%XX%')
假如有这样一列code的值为'AAA','AAB','BAA','BAB' ,如果where code like '%AB'条件,由于前面是模糊的,所以不能利用索引的顺序,必须一个个去找,看是否满足条件。这样会导致全索引扫描或者全表扫描。如果是这样的条件where code like 'A % ',就可以查找CODE中A开头的CODE的位置,当碰到B开头的数据时,就可以停止查找了,因为后面的数据一定不满足要求。这样就可以利用索引了。
4.MySQL主要提供2种方式的索引:B-Tree索引,Hash索引。
B树索引具有范围查找和前缀查找的能力,对于有N节点的B树,检索一条记录的复杂度为O(LogN)。相当于二分查找。
哈希索引只能做等于查找,但是无论多大的Hash表,查找复杂度都是O(1)。
显然,如果值的差异性大,并且以等值查找(=、<;、>;、in)为主,Hash索引是更高效的选择,它有O(1)的查找复杂度。
如果值的差异性相对较差,并且以范围查找为主,B树是更好的选择,它支持范围查找。
4.索引的注意事项
并非所有的数据库都以相同的方式使用索引。
作为通用规则,只有当经常查询索引列中的数据时,才需要在表上创建索引。索引占用磁盘空间,并且降低添加、删除和更新行的速度。
在多数情况下,索引用于数据检索的速度优势大大超过它的不足之处。但是,如果应用程序非常频繁地更新数据或磁盘空间有限,则可能需要限制索引的数量。
可以基于数据库表中的单列或多列创建索引。多列索引使您可以区分其中一列可能有相同值的行。
如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。例如,如果经常在同一查询中为姓和名两列设置判据,那么在这两列上创建多列索引将很有意义。
确定索引的有效性:检查查询的 WHERE 和 JOIN 子句。在任一子句中包括的每一列都是索引可以选择的对象。
对新索引进行试验以检查它对运行查询性能的影响。考虑已在表上创建的索引数量。
最好避免在单个表上有很多索引。检查已在表上创建的索引的定义。
最好避免包含共享列的重叠索引。检查某列中唯一数据值的数量,并将该数量与表中的行数进行比较。
比较的结果就是该列的可选择性,这有助于确定该列是否适合建立索引,如果适合,确定索引的类型。