solr(学习hybrisjava需要哪些基础)
1.学习hybris java需要哪些基础
hybris内容知识包括:Cockpit(ZK)/CockpitNG/CMS/Solr/Promotion/Mobile/OMS/Catalog design/PCM/OMS/Datahub/Accelerator。
WikiHybris 所有的资料都在hybris的wiki上,所以从high level上来说,比较好的一个途径是看wiki,做trail。hybris的trail 其实应该做几遍,知道每一步的流程具体是做什么的。
Project Implementation做hybris项目,会非常辛苦,我见过partner从早上8点多做到晚上12点。这对于某一个领域的能力会增加很快,不过对于hybris知识的广度可能未必。
Source Code我们都知道hybris的source code是可以被反编译的,可以大概看看其中的代码结构。wiki上很多资料写的其实并不全,并且由于资料多,很容易看过前面就忘了后面。
具体实现细节还需要看源代码来了解,例如hybirs core和core plus 的底层细节(如类型系统type system的启动和初始化),以及spring context scope等,这些细节都是需要看源代码来了解的。还包括一些正在发展的component, 如datahub的实现细节,在wiki上基本没有,必须看源代码才能知道其内部逻辑。
注:反编译的源代码不一定保证能和源source code一一对应,我就见过exception stack trace 和反编译出来的代码对应不上,到时候可能会一头雾水。阅读源代码的时候还可以用关系图来理解各个package之间的联系,从而将自己的知识网格化,这样不同的知识点能够互相连接起来。
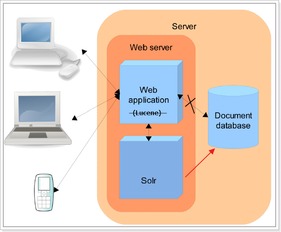
2.什么是solr,solr和solrCore
Lucene是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.
Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。它对外提供类似于Web-service的API接口。用户可以通过 下面主要说说需要注意的地方。 Solr的安装非常简单,下载solr的zip包后解压缩将dist目录下的war文件改名为solr。
war直接复制到tomcat5。5的webapps目录即可。
注意一定要设置solr的主位置。有三种方法。
我采用的是在tomcat里配置java:comp/env/solr/home的一个JNDI指向solr的主目录(example目录下),建立/tomcat55/conf/Catalina/localhost/solr。 xml文件。
观察这个指定的solr主位置,里面存在两个文件夹:conf和data。其中conf里存放了对solr而言最为重要的两个配置文件schema。
xml和solrconfig。xml。
data则用于存放索引文件。 schema。
xml主要包括types、fields和其他的一些缺省设置。 solrconfig。
xml用来配置Solr的一些系统属性,例如与索引和查询处理有关的一些常见的配置选项,以及缓存、扩展等等。 上面的文档对这两个文件有比较详细的说明,非常容易上手。
注意到schema。xml里有一个url 的配置,这里将url字段作为索引文档的唯一标识符,非常重要。
三、加入中文分词 对全文检索而言,中文分词非常的重要,这里采用了qieqie庖丁分词(非常不错:))。集成非常的容易,我下载的是2。
0。4-alpha2版本,其中它支持最多切分和按最大切分。
4.如何对solr建立的索引进行搜索
以下资料整理自网络,以及查看solr帮助文档。
主要分为两部分,第一部分是对《db-data-config.xml》的配置内容的讲解(属于高级内容),第二部分是DataImportHandler(属于基础),第三部分是对db-data-config.xml的进阶 第一部分是对《db-data-config.xml》 query是获取全部数据的SQL deltaImportQuery是获取增量数据时使用的SQL deltaQuery是获取pk的SQL parentDeltaQuery是获取父Entity的pk的SQL Full Import工作原理:执行本Entity的Query,获取所有数据;针对每个行数据Row,获取pk,组装子Entity的Query;执行子Entity的Query,获取子Entity的数据。 Delta Import工作原理:查找子Entity,直到没有为止;执行Entity的deltaQuery,获取变化数据的pk;合并子Entity parentDeltaQuery得到的pk;针对每一个pk Row,组装父Entity的parentDeltaQuery;执行parentDeltaQuery,获取父Entity的pk;执行deltaImportQuery,获取自身的数据;如果没有deltaImportQuery,就组装Query 限制:子Entity的query必须引用父Entity的pk 子Entity的parentDeltaQuery必须引用自己的pk 子Entity的parentDeltaQuery必须返回父Entity的pk deltaImportQuery引用的必须是自己的pk 第二部分是DataImportHandler 关于DataImportHandler的具体使用方法,详见下文,如果你英文超级好,那看这个链接吧:.mysql.jdbc.Driver" url="jdbc:mysql://localhost/dbname" user="db_username" password="db_password"/> 数据源也可以配置在solrconfig.xml中 属性type 指定了实现的类型。它是可选的。
默认的实现是JdbcDataSource。 属性 name 是datasources的名字,当有多个datasources时,可以使用name属性加以区分 其他的属性都是随意的,根据你使用的DataSource实现而定。
当然 你也可以实现自己的DataSource。 多数据源 一个配置文件可以配置多个数据源。
增加一个dataSource元素就可以增加一个数据源了。name属性可以区分不同的数据源。
如果配置了多于一个的数据源,那么要注意将name配置成唯一的。 例如: 然后这样使用 ..<entity name="one" dataSource="ds-1" 。
> .. .... 配置JdbcDataSource JdbcDataSource中的属性有 driver(必需的):jdbc驱动名称 url(必需的):jdbc链接 user:用户名 password:密。
5.如何监控ApacheSolr
Solr是一个Java应用,可以部署在Web容器中。
如果使用的是 Sun Java 1。6, 在启动命令行加上 -Dcom。
sun。management。
jmxremote 即可启用 JMX 监控。例如: java -Dcom。
sun。management。
jmxremote -jar start。jar配置时,需要JMX的用户名,口令,和jmx_url。
如果是本地相同用户监控,只要制定进程号即可,这种方式不需要用户名和口令,(只对Sun Java 1。6 有用),具体写法可参考,另一个开源工具sigar的文档。
监控时首要关注的是Java虚拟机的配置,包括堆空间大小,当前堆的使用大小等。然后关注的应该是索引文档的数量,最大值,以及各种查询,缓存的命中率,使用率等,具体如下: JVM 指标 activeThreadCount:活跃线程数量 CurrentHeapSize:当前堆大小 TotalHeapSize: 堆的总大小 Searcher 监控 Searcher Number of Docs Searcher Max Docs Query监控 Query Result Cache Evictions Query Result Cache Hit Ratio Query Result Cache Hits Query Result Cache Inserts Query Result Cache Lookups Query Result Cache Sizes Document监控 Document Cache Evictions Document Cache Hit Ratio Document Cache Hits Document Cache Inserts Document Cache Lookups Document Cache Sizes Filter 监控 Filter Cache Evictions Filter Cache Hit Ratio Filter Cache Hits Filter Cache Inserts Filter Cache Lookups Filter Cache Sizes Update 监控 Update Handler Adds Update Handler Commits Update Handler Autocommits Update Handler Optimizes Update Handler Rollbacks Update Handler ExpungeDeletes Update Handler DocsPending Update Handler DeletesById Update Handler DeletesByQuery Update Handler Errors 监控Solr后,可使用Hyperic HQ丰富功能,对采集的数据进行查看,展示,报警。
6.it基础知识
作为一个真正的IT人员,我们不仅要懂得高级语言的编程使用,更要懂得电脑基础的知识。这是我们成为杰出的IT人员的基石,只有踏上这些基础知识我们才能走的更高。
首先我们要懂得电脑是如何工作的?电脑的工作原理就是开和关两种状态,这是由其中的部件只有开和关这两种状态最稳定决定的。
而我们用0和1去表示他们,电脑将0和1进行了充分的组合,也就是部件的串联,造就了丰富多变各种各样的事物,也就是我们看电脑功能的强大。
可以通过0和1进行编码输入计算机,也可以通过解码将其还原成原来的事物。这就是电脑工作最基本的原理。
0和1编码也就是我们说的二进制Binary,二进制的出现正是伴随着计算机的诞生而出现的,计算机的一切工作计算都是由二进制编码完成的。就像十进制Decimal正是专门为我们人类使用方便而产生的。另外还有十六进制Hexadecimal,由于人类研究二进制比较复杂,才引出了十六进制去方便研究二进制。
而这些简单的二进制是如何和世界转变的呢?这里又引出了ASCII码,BCD码,国标码等这些都是帮助计算机实现其功能的必需品。
这些东西都是电脑正常工作的必备条件,只有我们把这些东西,弄明白了我们才能在计算机方面走的更高更远。
IT 人员必学的基础知识(二)——进制相互转化
二进制是计算机处理数据的工具。单位有位(bit),字节(Byte),千字兆(KB),兆字节(MB),千兆字节(GB)。
相互转换关系:1B=8bit,1KB=1024B,1MB=1024KB,1GB=1024MB。
二进制,八进制,十进制,十六进制之间的转换图:
其中二进制可以作为这几种之间相互转化的基础,通过二进制很多可以变得很简单:
IT人员必学基础知识(三)——编码理解
上篇说的二进制等之间的转换,而要完成这些转换,需要人为的定制一些规则,这就是第一篇提到的ASCII码,BCD码和国标码。
1、ASCII码,即美国标准信息交换码(American Standard Code for Information Interchanger), 包括了32个通用字符,10个十进制数码,52个英文大小写字母和34个专用符号。这是没有拓展的,最常用的。图:
2、BCD(Binary-Coded Decimal)码,又称为“二-十进制编码”专门解决用二进制数表示十进制数的问题。BCD制编码的方法有很多,通常有8421码,5421码等等。
例:13可以写作8421码0001 0011
3、国标码(GB2312),主要是编码汉字的,有两个7位二进制编码表示,即每个编码需要占两个字节,是针对中国一些信息编制的一些编码。
IT人员必学基础知识(四)——补充总结
这是计算机计算十进制运算时的大致过程,它将几种进制和几种编码运用到了极致。这就是计算机运用简单的事物早就不简单的事情。计算机中任何一个过程都需要运用到这些知识,另外还有原码,反码,补码等等。
在计算机内,定点数有3种表示法:原码、反码和补码。原码(true form)就是二进制定点表示法,即最高位为符号位,“0”表示正,“1”表示负,其余位表示数值的大小。
反码表示法规定:正数的反码与其原码相同;负数的反码是对其原码逐位取反,但符号位除外。补码(two's complement)表示法规定:正数的补码与其原码相同;负数的补码是在其反码的末位加1。