调查数据编码的基本方法(数据编码的基本内容包括哪些)
1.数据编码的基本内容包括哪些
数据编码数据的基本内容是:
通过编码可建立数据间的内在联系,便于计算机识别和管理。地理信息系统中主要的数据编码是服务于空间信息分析的地理编码。
即为识别图形点、线、面或格网位置及属性而建立的编码方法,包括拓扑编码和坐标编码。
前者是表示空间数据位置相邻逻辑关系的编码方法;后者是表示空间数据位置在某一坐标系统下的量度,可以是隐式的(对格网数据)或显式的。
扩展资料:
常见编码方案:
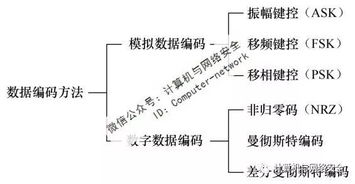
1、单极性码
在这种编码方案中,只适用正的(或负的)电压表示数据。单极性码用在电传打字机接口以及PC机和TTY兼容的接口中,这种代码需要单独的时钟信号配合定时,否则当传送一长串0或1时,发送机和接收机的时钟将无法定时,单极性码的抗噪声特性也不好。
2、极性码
在这种编码中,分别用正和负电压表示二进制数“0”和“1”。这种代码的电平差比单极码大,因而抗干扰特性好,但仍需另外的时钟信号。
3、双极性码
信号在三个电平(正、负、零)之间变化。一种典型的双极性码就是信号反转交替编码。在AMI信号中,数据流遇到“1”时使电平在正和负之间交替翻转,而遇到“0”时则保持零电平。
4、归零码
归零码(Return to Zero,RZ),即码元中间信号回归到零电平,比如从正电平到零电平的转换表示码元“0”,而从负电平到零电平表示码元“1”。
5、双相码
双相码要求每一位中都要有一个电平转换。因而这种代码的最大优点是自定时,同时双相码也有检测错误的功能,如果某一位中间缺少了电平翻转,则被认为是违例代码。
6、非归零电平编码
非归零电平编码(Non-Return to Zero Level,NRZ-L),即不使用0电平,用正电平表示“1”,负电平表示“0”。
7、非归零反相编码
非归零反相编码(Non-Return to Zero Inverted,NRZ-I),即当“1”出现时电平翻转,当“0”出现时电平不翻转。这种代码也叫差分码。
8、曼彻斯特码
曼彻斯特码(Manchester),高电平到低电平的转换边表示"0",低电平到高电平的转换边表示"1",位中间的电平转换边既表示数据代码,也作定时信号使用。曼彻斯特编码用在以太网中。
9、差分曼彻斯特码
差分曼彻斯特码(Differential Manchester),也叫做相位编码(PE);常用于局域网传输。在曼彻斯特编码中,每一位的中间有一跳变,“0”表示位的开头有跳变,“1”表示位的开头没有跳变,位中间的跳变既作时钟信号,又作数据信号。
10、多电平编码:
码元可取多个电平之一,每个码元可代表几个二进制位。
11、4B/5B编码
这是兆位快速以太网的光纤分布式数据接口(FDDI,Fiber Distributed Data Interface)中采用的信息编码方案。这种编码的特点是将欲发送的数据流每4bit作为一个组,每四位二进制代码由5位编码表示,这5位编码称为编码组(code group),并且由NRZI方式传输。
参考资料来源:搜狗百科-数据编码
2.统计调查的方法有哪些
统计调查的方法有:
1、普查
指专门组织的、全国性的、对全体调查对象普遍进行的一次性全面统计调查。
2、抽样调查
指根据概率理论,从全体调查对象中随机抽取一部分单位进行观察,取得样本统计调查数据,并据以推断总体的统计调查方法。
3、统计报表
是指在统计调查活动中用以对调查对象进行登记、搜集原始统计资料的表格。
4、重点调查
指在调查对象中,选择其中一部分重点单位所进行的调查。
5、典型调查
典型调查是一种非全面的专门调查,它是根据调查的目的与要求,在对被调查对象进行全面分析的基础上,有意识地选择若干具有典型意义的或有代表性的单位进行的调查。
扩展资料:
按调查对象包括的范围不同,可分为全面调查和抽样调查。
(1)全面调查是对被调查对象中所有的单位全部进行调查,其主要目的是要取得总体的全面、系统、完整的总量资料。如普查。全面调查要耗费大量的人力、物力、财力和时间。
(2)抽样调查是对被调查对象中一部分单位进行调查。如重点调查、典型调查、抽样调查和非全面统计报表等。
按登记时间是否连续,可分为经常性调查与一次性调查。
(1)经常性调查,是随着调查对象在时间上的发展变化,而随时对变化的情况进行连续不断的登记。其主要目的是获得事物全部发展过程及其结果的统计资料。
(2)一次性调查:是不连续登记的调查,它是对事物每隔一段时期后在一定时点上的状态进行登记。其主要目的是获得事物在某一时点上的水平、状况的资料。
参考资料来源:搜狗百科-统计调查
3.调查记录数据的方法有很多,还可以用什么,什么等多种方法
【教学目标】 知识与技能目标:1、让学生了解收集数据的目的; 2、让学生掌握收集数据的基本方法和途径; 3、掌握整理数据的几种常用方法; 4、根据数据信息对某些现象发表自己的看法。
过程与方法目标:经历收集数据的过程,了解数据收集的具体方法和基本要求;培养学生观察数据的能力,收集信息的能力,作出正确判断的能力。 情感、态度、价值观目标:让学生从数据的收集和整理中,掌握相关的日常生活和生产信息,作出明智的决策和判断,树立起正确的人生奋斗目标。
【教学重点、难点】 重点:1、了解收集数据的目的,掌握收集数据的方法和途径; 2、掌握用分类、排序、分组、编码等方法来整理数据; 难点:数据的分组、编码。 教学流程 教师组织 学生活动预设 设计意图 一、创设情境,引入课题 1.师:今天非常高兴,能与同学们一起来探讨数学问题。
2008年,第29届奥运会在北京取得圆满成功,现在我们来回顾下北京是如何取得奥运会主办权?(规定:得票超过52票获得奥运会举办权,但每轮淘汰得票最少的城市。) 第一次投票结果 参选城市 票数 北京 44票 多伦多 20票 。
分析整理后的数据得出结论.5 1、让学生掌握收集数据的基本方法和途径,觉得数学就在身边。 五、编码等方法整理数据。)
第一次投票结果 参选城市 票数 北京 44票 多伦多 20票 伊斯坦布尔 17票 巴黎 15票 大阪 6票 第二次投票结果 参选城市 票数 北京 56票 多伦多 22票 巴黎 18票 伊斯坦布尔 9票 师:参加投篮比赛 规则,每班3男3女、是否是一个身高做一套服装吗,现在我们来回顾下北京是如何取得奥运会主办权.5(女) 0、创设情境。 过程与方法目标,还有以分组编码的例子吗:1? ② 学生右眼视力跟性别有关吗、掌握整理数据的几种常用方法:6票淘汰了大阪.2(女) 1.5 1: 杭州西溪湿地的鸟类观察数据(资料来源!(学生自由发言? 三? ①学校停车场地方自行车的数量,会对这些数据做怎么样的整理?(师生共同回忆小结) 直接途径有; 间接途径有,引出课题 通过这个环节让学生对数据收集的途径有明确的认识。
提问、探索新知 (一)、排序 (2)分组.5 1。 【教学重点.2 0: ① 这组数据是用什么方法获得的,共同提高 1、调查;,掌握收集数据的方法和途径:56票选定出了北京作为2008年奥运会的主办城市,得出收集数据的途径和方法: 1,让学生感受到数据时非常有用的? 2、分组,在做服装前需要做什么、价值观目标: 6.0 0,感受选择举办奥运会城市的方法 积极参与思考、女生各10名右眼裸视的检测结果、迁移拓展,医生对某一组学生体温测试、排序?(请标4000px的同学站起来) ③身高为多少的同学的身高才是差不多呢,我们还有哪些获取数据的方法、让学生了解收集数据的目的、合作交流,对数据的收集途径有较深的体会,数数 自报身高 积极思考,积极思考. 认真观察、实验等方法,数据收集的方法主要有哪些?怎样处理这组数据.6(女) 1,作为这个项目的班级得分? 2? (2)从这些数据中:收集下列数据你会采用什么方法; 2、以下是某校七年级男,你想了解神七的有关数据、根据整理后的数据发表自己的看法,能与同学们一起来探讨数学问题、归纳小结? 说说收集数据的途径和方法 (1)在平时的生活中、课件给出两套服装:如何选拔运动员,根据自己的生活经验猜想,比如,前期有很多的工作准备:经历收集数据的过程,了解数据收集的具体方法和基本要求. 学生谈收获.数据的整理 1。
问,这6位同学的进篮总数,这节课我们就一起来进行数据的收集和整理,树立起正确的人生奋斗目标,内化能力 师;难点、练一练【教学目标】 知识与技能目标。 ⑶数据如何说话——用分类。
巩固理解收集数据的途径和方法 通过这个活动后.(板书课题、分组、测量:今天非常高兴:得票超过52票获得奥运会举办权、应用新知 1.1 1! 3? 四、编码等方法来整理数据。 (二)!.3(女) 1? ②? 老师启发…… 练习. 课本作业题; .2(女) 0,作出正确判断的能力:1、使用互联网查询等:观察、学生观察黑板上凌乱的数据,收集信息的能力.2 1,教师归纳补充) ⑴数据会说话——表明数据是有用的 ⑵怎样让数据说话——离不开数据的收集;培养学生观察数据的能力: 0:30 (1)这里的数据是通过什么方法收集得到的:15~11.7(女) 1。
2008年、生活中。 下面我们一起来小结; ⑤神舟七号飞船发射成功; 3. 作业本 六?(规定.数据的收集 师、编码、测量: 第一次投票:数据的分组。
学生举手回答. 一起小结 举手。投篮每人10次、编码 学生聆听,引入课题 1.师,但每轮淘汰得票最少的城市:运动会即将开始:浙江野鸟会) 鸟的种类 黑尾腊嘴鹊 八哥 白鹡鸰 雉鸡 乌鸦 白鹭 山斑鸠 家燕 翠鸟 数 量 4 3 14 2 3 2 1 4 4 2003年3月1日 8:以班级为单位? 活动二,也可以查找文献资料,按照得分由高到低取前3名、排序:(1)分类.4(女) 1; ③一定量的水在加热时温度的变化:查阅文献资料,师生共同总结 学生记录作业内容 经历对数据的理解; ④在体检中; ①:让学生从数据的收集和整理中、态度,选择其中一套作为我校彩球队的队服?总要有个标准吧; 。
4.问卷调查数据分析方法有哪些
一、数据分析思维
首先学会做基础数据分析并不难,掌握一些必要的知识就能很快上手,学习数据分析的路径如下共三部曲:数据类型的识别、研究方法的选择、结果分析。
(1) 数据类型的识别
数据类型是一切研究的基石,也是数据研究思维的最基本且最关键的思维。确认数据的真实准确性后,即完成数据清理后,可对数据类型进行区分,一切数据均可分为两种类型,包括定性数据和定量数据。
· 定量:数字有比较意义,比如数字越大代表满意度越高,量表为典型定量数据
· 定类:数字无比较意义,比如性别,1代表男,2代表女
(2)研究方法的选择
数据类型确认后,此时即可理解数据分析方法的选择。像SPSSAU在设计时,区分数据类型的同时,还区分X和Y。比如性别和是否吸烟的关系,X是性别,Y为是否吸烟。X和Y均为定类数据。此时则应该选择“交叉卡方”分析。
第一步即选对研究方法,即数据类型的识别。
第二步即结合研究目的进行分析,常见的研究目的包括:数据基本描述、影响关系研究、差异关系研究及其它关系。
请点击输入图片描述
(3)分析结果
分析基础比较薄弱,可使用SPSSAU进行分析,系统会自动生成指标解读报告。
请点击输入图片描述
二、分析思路模板
研究框架是分析的核心,一般可分为非量表和量表问卷,然后再对照着框架进行分析即可。
量表类问卷最大的特点是:非常多的量表题,而且量表题对应着‘变量’或者‘维度’。便于研究‘变量’间的关系情况。以及可以使用信度、效度、因子分析等方法。
非量表题其最大的特点为大部分为单选题、多选题或者排序填空题等,但很少 有出现量表题(是量表题是指类似答项为“非常不同意”,“比较不同意”,“中立”,“比较同意”和 “非常同意”之类的问题)更多是使用基本频数分析和交叉分析等,同时使用图形和表格进行多样化展示。
5.栅格数据的编码方法
编码方法 在栅格文件中,每个栅格只能赋予一个唯一的属性值,所以属性个数的总数是栅格文件的行数乘以列数的积,而为了保证精度,栅格单元分得一般都很小,这样需要存储的数据量就相当大了。
通常一个栅格文件的栅格单元数以万计。但许多栅格单元与相邻的栅格单元都具有相同的值,因此使用了各式各样的数据编码技术与压缩编码技术。
主要的编码技术简介如下:(一)直接栅格编码 直接栅格编码是将栅格数据看作一个数据短阵,逐行或逐列逐个记录代码。可每行从左到右逐个记录,也可奇数行从左到右,偶数行从右到左记录,为特定目的也可采用其它特殊顺序。
通常称这种编码的图像文件为栅格文件,这种网格文件直观性强,但无法采用任何种压缩编码方法。图2.1 (c)的栅格编码为:4,4,4,4,7,7,7,7;4,4,4,4,4,7,7,7;4,4,4,4,9,9,7,7;0,0,4,9,9,9,7,7;0,0,0,9,9,9,7,7;0,0,0,9,9,9,9,9;0,0,0,0,9,9,9,9;0,0,0,0,0,9,9,9。
可用程序设计语言按顺序文件或随机文件记录这些数据。(二)链式编码 链式编码又称弗里曼链码或世界链码。
它由某一原始点和一系列在基本方向上数字确定的单位矢量链。基本方向有东、东南、南、西南、西、西北、北、东北等8个,每个后继点位于其前继点可能的8个基本方位之一。
8个基本方向的代码可分别用0,1,2,3,4,5,6,7表示,既可按顺时针也可按逆时针表示。栅格结构按逆时针编码上图(2)可记录为:1,3,7,7,7,6,6,5,4。
其中前两个数字1与3表示线状物起点的坐标,即在第一行第三列,从第三个数字起表示单位矢量的前进方向。链式编码有效地压缩了栅格数据,尤其对多边形的表示最为显著,链式编码还有一定的运算能力,对计算长度、面积或转折方向的凸凹度更为方便。
比较适于存储图形数据。但对边界做合并和插入等修改编辑工作很难实施,而且对局部修改要改变整体结构,效率较低。
(三)游程编码 游程编码是栅格数据压缩的重要且比较简单的编码方法。它的基本思路是:对于一幅栅格图像,常有行或列方向相邻的若干点具有相同的属性代码,因而可采用某种方法压缩重复的记录内容。
方法之一是在栅格数据阵列的各行或列象元的特征数据的代码发生变化时,逐个记录该代码及相同代码重复的个数,从而可在二维平面内实现数据的大量压缩。另一种编码方案是在逐行逐列记录属性代码时,仅记录下发生变化的位置和相应的代码。
图2.1 (c)栅格结构按游程编码方法可记录为:第一行4,47,4 第二行4,57,3 第三行4,49,27,2 第四行0,24,19,37,2 第五行0,39,37,2 第六行0,39,5 第七行0,49,4 第八行0,59,3 在这个例子中,原本64个栅格数据,只用了40数值就完整地表示了出来,可见用游程编码方法压缩数据是十分有效的。游程编码的编码和解码的算法都比较简单,占用的计算机资源少,游程编码还易于检索、叠加、合并等操作,在栅格单元分得更细时,数据的相关性越强,压缩效率更高,数据量并没有明显增加。
因此,该编码适合微型计算机等中央处理器处理速度慢,存储容量小的设备进行图像处理。(四)块式编码 块式编码是游程编码扩展到二维空间的情况,游程编码是在一维状态记录栅格单元的位置和属性,如果采用正方形区域作为记录单元,每个记录单元包括相邻的若干栅格,数据结构由记录单元中左上角的栅格单元的行、列号(初始位置)和记录单元的边长(半径)与记录单元的属性代码三部分组成,这便是块式编码。
因此可以说,游程编码是块式编码的特殊情况,块式编码是游程编码的一般形式。图2.1 (c)表示的栅格结构按块式编码方法可记录为:(1,1,3,4),(1,4,1,4),(1,5,1,7),(1,6,2,7),(1,8,1,7);(2,4,1,4),(2,5,1,4),(2,8,1,7);(3,4,1,4),(3,5,2,9),(3,7,2,7);(4,1,2,0),(4,3,1,4),(4,4,1,9);(5,3,1,0),(5,4,2,9),(5,6,1,9),(5,7,1,7),(5,8,1,7);(6,1,3,0),(6,6,3,9);(7,4,1,0),(7,5,1,9),(8,4,1,0),(8,5,1,0)。
从以上论述的块式编码的编码原理可知,一个记录单元所表示的地理数据相关性越强,也即记录单元包含的正方形边长越长,压缩效率越高。而地理数据相关性差时,也即多边形边界碎杂时,块式编码的效果较差。
块式编码的运算能力弱,必要时其编码的栅格数据须通过解码转换成栅格矩阵编码的数据形式才能顺利进行。块式编码在图像合并、插入、面积计算等功能方面较强。
(五)四叉树数据结构 四叉树编码又名四元树编码,可以通俗理解为一个具有四分枝结构的树,它具有栅格数据二维空间分布的特征,这是一种更为有效的编码方法。四叉树编码将整个图形区域按照四个象限递归分割成2n*2n象元阵列,形成过程是:将一个2*2图像分解成大小相等的四部分,每一部分又分解成大小相等的四部分,就这样一直分解下去,一直分解到正方形的大小正好与象元的大小相等为止,即逐步分解为包含单一类型的方形区域(均值块),最小的方形区域为一个栅格单元。
这个倒向树状的图中“○”表示可继续分割的方形区域;“□”表示具有同类属性的方形区域;“■”表示不能再分的单个(最小)象元栅格,即所谓的树叶,树叶表示的是具有单一类型的地物或是符合既定要求的少数几种地物,可以在任意层上。通过以上对四叉树结构的分析,可发现它有以下特点:⑴ 存储空间小。
6.数据调查的具体方法是什么
设计调查表格
在确定调查目的。调查任务、调查单位、调查对象和报告单位等一系列条目之后,要根据调查的需要,将所要了解的数据列为设计表格中的每一个项目,并且编制填表说明和报告时间,尔后发给调查单位和调查对象在规定的时间内填报。有时,也可由调查人员直接向调查单位或调查对象提问、计量、观察。
摘录有关数据
在报告单位的数据资料和在调查研究过程中调查对象提供的数据里,有一些是与调查研究课题无关的,调查者应根据调查工作的实际需要,对已掌握的数据资料进行筛选、摘录,把有关、有用的数据摘录出来。如中国社会科学院青少年研究所在汇编《中国1982年青少年人口数据资料》一书时,就采取了这种方法。他们以我国青少年人口自我状况和社会现象诸方面的数据为编辑依据,从《中国1982年人口普查10%抽样资料》一书,以及各类报刊登载的有关这方面的数据资料中进行摘编。如在人口普查的许多现有表格中,有许多是与该书所需要的数据无关的,其中有23类有关系,他们就把这23类抽出来汇编整理。
搜集原始记录
一般情况下,每个单位都有自己的工作记事本,记载本单位所做的主要工作,这些都属于原始记录,比较真实、可信。在开展调查活动时要注意搜集。查阅这些原始记录中的有关数据。
实践已经表明,数据调查是容易受人为因素的影响的。“大跃进”时期,在“浮夸风”的影响下,农村多报粮食产量的现象泛滥成灾,而且谁报得越多,谁就是模范。如有人曾将粮食亩产量报到一万斤。因此维护数据调查的科学性和严肃性是十分重要的。在开展数据调查时,要防止虚报、估报、误报等现象发生,一是不能完全依照领导的意图搞数据调查,特别是领导要求夸大或缩小某些事实数据时。二是要注意反复核实数据,如查阅原始记录,询问数据的来源。同时还可以和其他调查方法相结合进行验证,如抽样调查法。三是加强对统计调查工作者的办公培训。防止在填报表格中产生不必要的误差。
7.统计调查方法都有哪些
朋友,你好!统计的调查方式,可以按照不同的标志划分为不同的类别。
(一)、按调查对象的范围分,可分为全面调查和非全面调查。全面调查又称普查,是指对每一个调查单位都要进行调查。非全面调查是指仅对总体中的一部分总体单位进行调查。包括:1、重点调查,2、典型调查,3、抽样调查。
重点调查是指只对总体中的重点单位进行调查,重点单位是指(1)、工作中的重点。(2)、这些重点单位的标志值在总体标志总量中占绝大部分。
典型调查是指从总体中预先选择具有代表性的单位进行调查。典型既有好的典型,也有坏的典型。
抽样调查简称抽查,是指按随机性原则从总体中抽取一部分单位进行调查,然后,根据样本总体的数量特征推断全及总体的数量特征。抽查的主要特点是随机性、推断性。
(二)、按调查的连续性来分,可分为一次性调查和经常性调查。一次性调查是指每隔一段时间进行一次调查,例如;我国全国人口普查每十年进行一次。经常性调查是指每天都要登记,例如,各单位考勤。
(三)、按调查的组织方式不同,可分为统计报表和专门调查。专门调查包括:普查,典型调查,重点调查,抽样调查。统计报表是由国家定期地从上往下布置,下级一级一级向上填报的报告制度,也是国家定期的一种调查组织方式。专门调查是指对一些专门问题进行调查,例如:海洋普查,是专门调查海洋的,农业普查是专门调查农业的
(四)、按调查的方法不同,可分为直接观察法、报告法和询问法。询问法又分为书面询问法和口头询问法。直接观察法是指统计人员直接到现场,报告法就是提供报表。
8.计算机中常用的数据编码有哪些
大部分电脑要用于信息管理,因此,需要把有关的信息进行二进制编码。国际上通用的是ASCII码,即美国标准信息交换码,它用七位二进制编码来表示十进制数、英文字母和常用符号,如运算符、括号、标点符号、标识符等,还有一些控制符,一共可以表示128个字符。
其中十个阿拉伯数字,五十二个大小写拉丁字母,32个标点符号和控制符和运算符,以及34个控制符。
ASCII码是为信息交换规定的标准,由于字符数量有限,编码简单,所以输入、存储、内部处理时也往往使用这种标准。
由于中国的汉字数量众多,所以汉字编码要用两个字节。汉字的国家标准编码是GB2312-80,这个标准用两个字节构成一个汉字字符编码,规定第一个字节和第二个字节的最高位均为1,通常用十六进制数表示。如“啊”字的编码是B0A1。
希望我能帮助你解疑释惑。