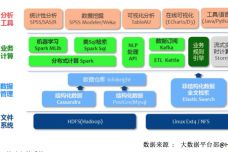
研究大数据的方法方面(大数据分析的常用方法)
1.大数据分析的常用方法有哪些
(预测性分析能力)
数据挖掘可以让分析员更好的理解数据,而预测性分析可以让分析员根据可视化分析和数据挖掘的结果做出一些预测性的判断。
(数据质量和数据管理)
数据质量和数据管理是一些管理方面的最佳实践。通过标准化的流程和工具对数据进行处理可以保证一个预先定义好的高质量的分析结果。 (可视化分析)
不管是对数据分析专家还是普通用户,数据可视化是数据分析工具最基本的要求。可视化可以直观的展示数据,让数据自己说话,让观众听到结果。 SemanticEngines(语义引擎)
我们知道由于非结构化数据的多样性带来了数据分析的新的挑战,我们需要一系列的工具去解析,提取,分析数据。语义引擎需要被设计成能够从“文档”中智能提取信息。
DataMiningAlgorithms(数据挖掘算法)
可视化是给人看的,数据挖掘就是给机器看的。集群、分割、孤立点分析还有其他的算法让我们深入数据内部,挖掘价值。这些算法不仅要处理大数据的量,也要处理大数据的速度。
2.收集大数据的方法有哪些
主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等,它们分别从不同的角度对数据进行挖掘。
分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。回归分析方法反映的是事务数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系,其主要研究问题包括数据序列的趋势特征、数据序列的预测以及数据间的相关关系等。
扩展资料:传统的聚类分析计算方法主要有如下几种:1、划分方法(partitioning methods) 给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K<N。而且这K个分组满足下列条件:(1) 每一个分组至少包含一个数据纪录。
(2)每一个数据纪录属于且仅属于一个分组(注意:这个要求在某些模糊聚类算法中可以放宽);对于给定的K,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好。而所谓好的标准就是:同一分组中的记录越近越好,而不同分组中的纪录越远越好。
使用这个基本思想的算法有:K-MEANS算法、K-MEDOIDS算法、CLARANS算法;大部分划分方法是基于距离的。给定要构建的分区数k,划分方法首先创建一个初始化划分。
然后,它采用一种迭代的重定位技术,通过把对象从一个组移动到另一个组来进行划分。一个好的划分的一般准备是:同一个簇中的对象尽可能相互接近或相关,而不同的簇中的对象尽可能远离或不同。
还有许多评判划分质量的其他准则。传统的划分方法可以扩展到子空间聚类,而不是搜索整个数据空间。
当存在很多属性并且数据稀疏时,这是有用的。为了达到全局最优,基于划分的聚类可能需要穷举所有可能的划分,计算量极大。
实际上,大多数应用都采用了流行的启发式方法,如k-均值和k-中心算法,渐近的提高聚类质量,逼近局部最优解。这些启发式聚类方法很适合发现中小规模的数据库中小规模的数据库中的球状簇。
为了发现具有复杂形状的簇和对超大型数据集进行聚类,需要进一步扩展基于划分的方法。2、层次方法(hierarchical methods) 这种方法对给定的数据集进行层次似的分解,直到某种条件满足为止。
具体又可分为“自底向上”和“自顶向下”两种方案。例如在“自底向上”方案中,初始时每一个数据纪录都组成一个单独的组,在接下来的迭代中,它把那些相互邻近的组合并成一个组,直到所有的记录组成一个分组或者某个条件满足为止。
代表算法有:BIRCH算法、CURE算法、CHAMELEON算法等;层次聚类方法可以是基于距离的或基于密度或连通性的。层次聚类方法的一些扩展也考虑了子空间聚类。
层次方法的缺陷在于,一旦一个步骤(合并或分裂)完成,它就不能被撤销。这个严格规定是有用的,因为不用担心不同选择的组合数目,它将产生较小的计算开销。
然而这种技术不能更正错误的决定。已经提出了一些提高层次聚类质量的方法。
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析按照涉及的变量的多少,分为一元回归和多元回归分析。
按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。
这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。
1、Linear Regression线性回归 它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。
在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
多元线性回归可表示为Y=a+b1X +b2X2+ e,其中a表示截距,b表示直线的斜率,e是误差项。多元线性回归可以根据给定的预测变量(s)来预测目标变量的值。
2、Polynomial Regression多项式回归 对于一个回归方程,如果自变量的指数大于1,那么它就是多项式回归方程。如下方程所示:y=a+bx2,在这种回归技术中,最佳拟合线不是直线。
而是一个用于拟合数据点的曲线。参考资料:百度百科-回归分析 参考资料:百度百科-聚类 参考资料:百度百科-分类 参考资料:百度百科-关联规则。
3.大数据可以应用在哪些方面
可以应用在云计算方面。
大数据具体的应用:
1、洛杉矶警察局和加利福尼亚大学合作利用大数据预测犯罪的发生。
2、google流感趋势(Google Flu Trends)利用搜索关键词预测禽流感的散布。
3、统计学家内特.西尔弗(Nate Silver)利用大数据预测2012美国选举结果。
4、麻省理工学院利用手机定位数据和交通数据建立城市规划。
5、梅西百货的实时定价机制。根据需求和库存的情况,该公司基于SAS的系统对多达7300万种货品进行实时调价。
6、医疗行业早就遇到了海量数据和非结构化数据的挑战,而近年来很多国家都在积极推进医疗信息化发展,这使得很多医疗机构有资金来做大数据分析。
7、及时解析故障、问题和缺陷的根源,每年可能为企业节省数十亿美元。
8、为成千上万的快递车辆规划实时交通路线,躲避拥堵。
9、分析所有SKU,以利润最大化为目标来定价和清理库存。
10、根据客户的购买习惯,为其推送他可能感兴趣的优惠信息。
扩展资料:
大数据的用处:
1、与云计算的深度结合。大数据离不开云处理,云处理为大数据提供了弹性可拓展的基础设备,是产生大数据的平台之一。
自2013年开始,大数据技术已开始和云计算技术紧密结合,预计未来两者关系将更为密切。除此之外,物联网、移动互联网等新兴计算形态,也将一齐助力大数据革命,让大数据营销发挥出更大的影响力。
2、科学理论的突破。随着大数据的快速发展,就像计算机和互联网一样,大数据很有可能是新一轮的技术革命。可能会改变数据世界里的很多算法和基础理论,实现科学技术上的突破。
参考资料:
百度百科--大数据
4.大数据 统计分析方法有哪些
您好朋友,上海献峰科技指出:常用数据分析
1. 聚类分析、
2.因子分析、
3.相关分析、
4.对应分析、
5.回归分析、
6.方差分析;
问卷调查常用数据分析方法:描述性统计分析、探索性因素分析、Cronbach'a信度系数分析、结构方程模型分析(structural equations modeling) 。 数据分析常用的图表方法:柏拉图(排列图)、直方图(Histogram)、散点图(scatter diagram)、鱼骨图(Ishikawa)、FMEA、点图、柱状图、雷达图、趋势图。
希 望 采纳不足可追问
5.大数据分析方法有哪些,大数据分析方法介绍
1. 描述型分析:最常见的分析方法。在业务中,这种方法向数据分析师提供了重要指标和业务的衡量方法。例如,每月的营收和损失账单。数据分析师可以通过这些账单,获取大量的客户数据。了解客户的地理信息,就是“描述型分析”方法之一。利用可视化工具,能够有效的增强描述型分析所提供的信息。
2. 诊断型分析:通过评估描述型数据,诊断分析工具能够让数据分析师深入地分析数据,钻取到数据的核心。良好设计的BI dashboard能够整合:按照时间序列进行数据读入、特征过滤和钻取数据等功能,以便更好的分析数据。
3. 预测型分析:预测型分析主要用于进行预测。事件未来发生的可能性、预测一个可量化的值,或者是预估事情发生的时间点,这些都可以通过预测模型来完成。
4. 指令型分析:指令模型基于对“发生了什么”、“为什么会发生”和“可能发生什么”的分析,来帮助用户决定应该采取什么措施。通常情况下,指令型分析不是单独使用的方法,而是前面的所有方法都完成之后,最后需要完成的分析方法。
6.大数据的统计分析方法有哪些
未至科技小蜜蜂网络信息雷达是一款网络信息定向采集产品,它能够对用户设置的网站进行数据采集和更新,实现灵活的网络数据采集目标,为互联网数据分析提供基础。
未至科技显微镜是一款大数据文本挖掘工具,是指从文本数据中抽取有价值的信息和知识的计算机处理技术, 包括文本分类、文本聚类、信息抽取、实体识别、关键词标引、摘要等。基于Hadoop MapReduce的文本挖掘软件能够实现海量文本的挖掘分析。CKM的一个重要应用领域为智能比对, 在专利新颖性评价、科技查新、文档查重、版权保护、稿件溯源等领域都有着广泛的应用。
未至科技数据立方是一款大数据可视化关系挖掘工具,展现方式包括关系图、时间轴、分析图表、列表等多种表达方式,为使用者提供全方位的信息展现方式。
7.大数据分析普遍存在的方法及理论有哪些
PEST分析法
PEST分析理论主要用于行业分析。PEST分析法用于对宏观环境的分析。宏观环境又称一般环境,是指影响一切行业和企业的各种宏观力量。
对宏观环境因素作分析时,由于不同行业和企业有其自身特点和经营需要,分析的具体内容会有差异,但一般都应对政治、经济、技术、社会,这四大类影响企业的主要外部环境因素进行分析。
2.逻辑树分析法
逻辑树分析理论课用于业务问题专题分析。逻辑树又称问题树、演绎树或分解树等。逻辑树是分析问题最常使用的工具之一,它将问题的所有子问题分层罗列,从最高层开始,并逐步向下扩展。
把一个已知问题当成树干,然后开始考虑这个问题和哪些相关问题有关。
8.收集数据的方法有哪些
收集方法
1、调查法
调查方法一般分为普查和抽样调查两大类。
2、观察法
主要包括两个方面:一是对人的行为的观察,二是对客观事物的观察。观察法应用很广泛,常和询问法、搜集实物结合使用,以提高所收集信息的可靠性。
3、实验方法
实验方法能通过实验过程获取其他手段难以获得的信息或结论。
实验方法也有多种形式,如实验室实验、现场实验、计算机模拟实验、计算机网络环境下人机结合实验等。现代管理科学中新兴的管理实验,现代经济学中正在形成的实验经济学中的经济实验,实质上就是通过实验获取与管理或经济相关的信息。
4、文献检索
文献检索就是从浩繁的文献中检索出所需的信息的过程。文献检索分为手工检索和计算机检索。
5、网络信息收集
网络信息是指通过计算机网络发布、传递和存储的各种信息。收集网络信息的最终目标是给广大用户提供网络信息资源服务,整个过程经过网络信息搜索、整合、保存和服务四个步骤,
参考资料来源:搜狗百科-信息收集